
Multimodal AI Model Limitations: Why They Matter Now
multimodal AI model limitations. Multimodal AI isn’t living up to the hype—at least not yet. While these systems that combine text, images, video, and audio sound impressive on paper, they keep stumbling over challenges humans navigate without thinking twice. If you’re considering AI solutions for business, knowing where these models fall short could save you from expensive mistakes.
The reality check comes when you see what happens outside controlled demos. Companies rolling out multimodal systems keep hitting the same walls: context gets lost, meanings get mixed up, and performance tanks when it matters most. Let’s break down where these systems struggle and why it’s happening.
Understanding Multimodal AI Architecture: multimodal AI model limitations
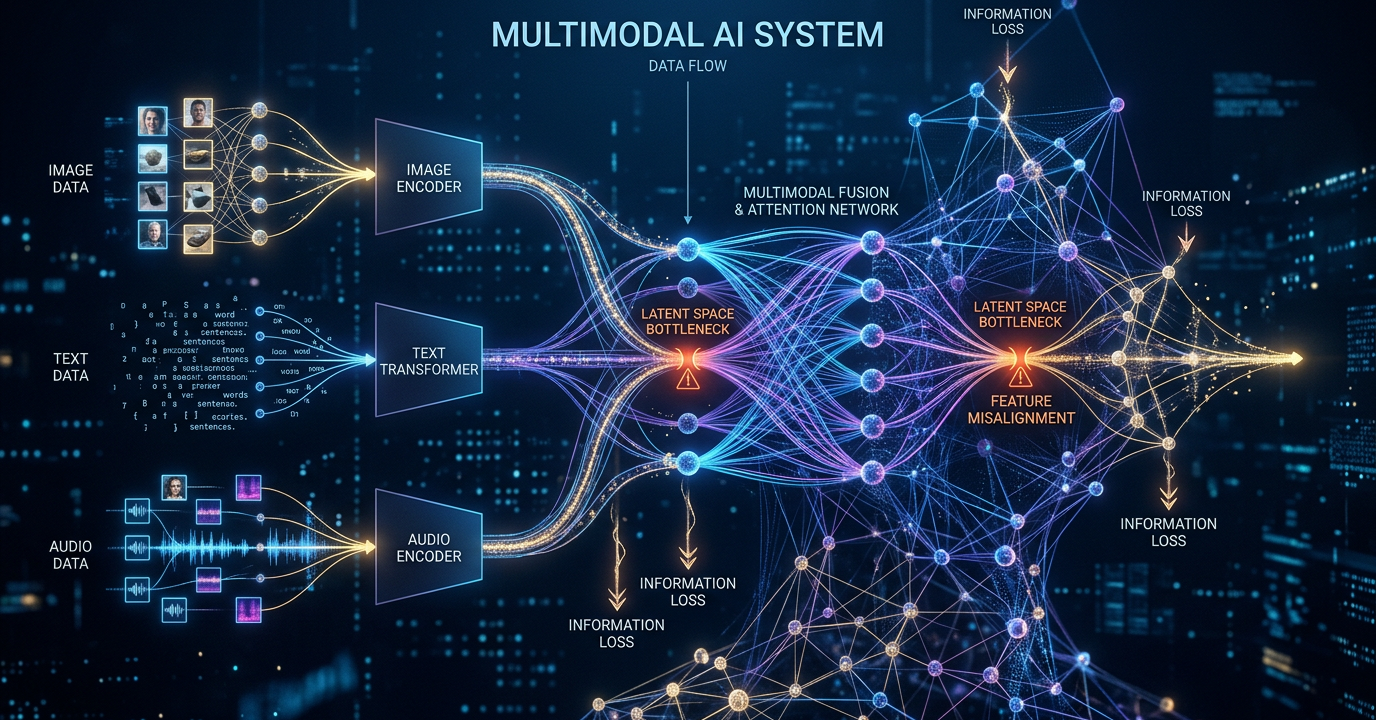
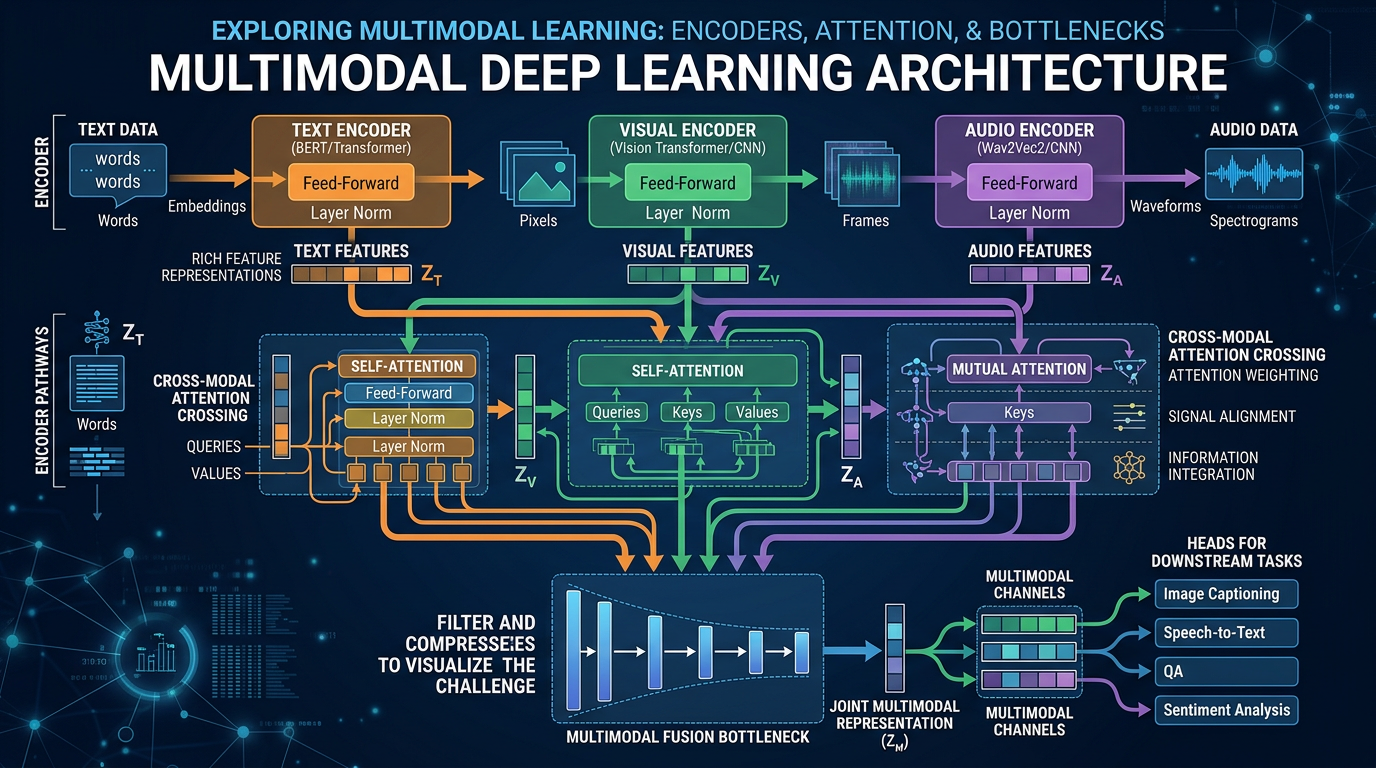
At their core, multimodal systems juggle different types of information at once. They have components for handling pictures, another for text, and maybe another for sound—all trying to work together. The idea makes sense: more inputs should mean smarter outputs, right?
Here’s where things get messy. Each data type needs special treatment before the system can even start making sense of it. Photos get resized and analyzed for features. Words get chopped up and converted to numbers. Sounds get broken into frequencies. By the time all this prepped data meets in the middle, some meaning has already slipped through the cracks.
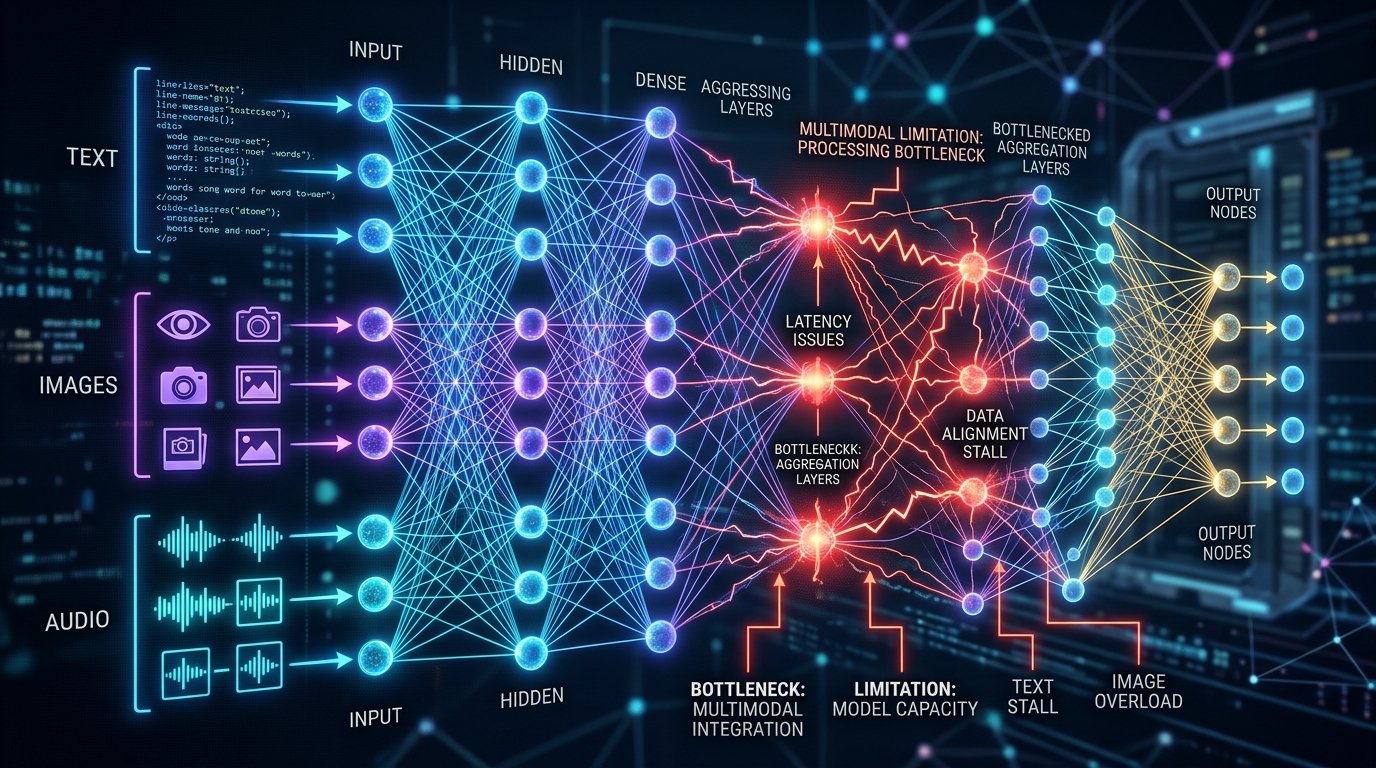
The real headache comes when trying to merge these different streams. Early attempts just shoved everything together. Newer methods use fancy attention mechanisms, but bottlenecks still form where information combines. It’s like trying to merge six lanes of traffic into two—something’s bound to get stuck.
Then there’s the sheer computing power needed. Processing one image with text might require billions of calculations. Add audio and you’re looking at server farms most companies can’t afford. Training these systems demands datasets so large they’d make your IT department weep.
Different data types just don’t play by the same rules. Words convey meaning directly. Pictures show relationships. Sounds carry emotion and rhythm. Getting AI to properly weigh all these factors? We’re not there yet.
Current Context Processing Challenges
Where multimodal AI really struggles is understanding context across different inputs. Show it a video of someone speaking Spanish while gesturing to objects, and watch the confusion unfold. The system needs to track visuals, recognize language, and connect sounds to meanings—all at once.
Time-based tasks trip these systems up constantly. They’re decent at analyzing static images or short audio clips. But ask them to follow a sequence of events in a video? That’s when you see the wheels come off. Human toddlers handle this better than our most advanced AI.
Cross-modal mix-ups happen all the time. Take a photo of a tennis player by a pool with the caption “She won the championship.” You’d know it’s about tennis. Many AI systems fixate on the pool instead. The connections we make instantly still elude machines.
Conflicting inputs really throw these systems for a loop. If a stop sign appears in an image but someone says “go” in the audio, which should it believe? Current models don’t actually decide—they just go with whatever their training emphasized more. Not exactly sophisticated reasoning.
Longer content pushes these systems to their limits. The math gets exponentially heavier with more data, so models often cut corners by sampling or truncating. Important details get lost in the process, like trying to understand a novel by reading every tenth page.
Abstract thinking remains a major weak spot. These systems can describe what they see but struggle with why it matters. They’ll list objects in a political cartoon perfectly while missing the satire entirely.
Real-World Failures and Case Studies
Nothing exposes AI’s flaws like actual users trying to get work done. One online retailer learned this the hard way with their multimodal product search. Combining images, descriptions, and reviews sounded great—until customers started uploading photos.
The system couldn’t recognize the same product shot from different angles or lighting. Where humans see a black shoe whether it’s photographed in sunlight or shadow, the AI saw completely different items. Sales took a 12% hit from frustrated shoppers.
Hospitals testing diagnostic AI hit different problems. The system analyzed medical images alongside patient histories—until it encountered conflicting clues. When scans suggested one condition but symptoms pointed elsewhere, the AI’s confidence often outweighed its accuracy.
Self-driving cars show how dangerous these gaps can be. Cameras, radar, and lidar sometimes disagree—like when wet roads reflect light in ways that look like obstacles. Current systems lack robust ways to resolve these disagreements safely.
Content moderation AI keeps embarrassing itself too. These systems need to understand images, text, and video context together. But without cultural knowledge, they either flag harmless posts or miss actual violations. Remember when an AI blocked historical photos thinking they violated policies?
Translation services adding visual context found it backfires sometimes. While helpful for humans, machines often overweight images at the expense of language. You get translations that sound right but miss nuances—like translating “bank” as a financial institution when the picture shows a river.

How Researchers Are Addressing These Gaps
The AI community isn’t ignoring these problems. Smarter fusion techniques lead the charge—instead of brute-forcing data together, new methods try to respect each type’s unique qualities. Think of it as a meeting where everyone gets to speak their native language.
Contrastive learning shows promise for aligning different data types. By training models to recognize when images and text match, they develop better shared understanding. Early tests suggest this helps with cross-modal reasoning.
Another approach uses specialized “experts” for each data type within larger systems. Visual data gets processed differently than text or audio, with gatekeepers deciding how much weight each gets. It’s like having translators at the UN who actually understand the topics being discussed.
Time-aware models are getting attention too. New architectures try to capture how information changes over sequences, which could help with video understanding. Current systems treat frames like unrelated photos—no wonder they miss the plot.
Researchers are also teaching AI to admit uncertainty. Instead of bluffing with false confidence, newer models can flag when inputs conflict or seem ambiguous. For high-stakes uses like healthcare, this honesty could prevent dangerous mistakes.
Synthetic training data helps expose systems to tough cases before they hit the real world. By generating examples with conflicting signals or edge cases, models learn to handle ambiguity better. It’s like flight simulators for AI—crash in training so you don’t crash in production.
For deeper understanding of how these solutions fit into broader AI development, see our coverage of emerging AI architectures.

What This Means for Enterprise Adoption
Businesses eyeing multimodal AI need to keep expectations grounded. These systems can add value, but only if deployed where their strengths outweigh their flaws. Knowing the limitations helps avoid costly missteps.
Customer service shows where multimodal works well—agents reviewing both chat history and customer video can spot issues faster. But expecting AI to perfectly reconcile every conflicting clue? We’re years away from that.
Testing needs to get real. Controlled environments miss the chaos of actual use. Throw contradictory data, weird edge cases, and ambiguous situations at your systems before customers do.
For critical decisions, keep humans involved. Have AI flag uncertain cases rather than guessing. This approach captures efficiency gains without betting the farm on imperfect automation.
Explainability matters too. When systems make calls, you need to know which inputs drove the decision. This transparency builds trust and helps identify systematic failures.
Remember—performance varies wildly by domain. A system crushing product recommendations might bomb at medical analysis. Test specifically for your use case, not just general benchmarks.
Budget for serious customization. Off-the-shelf multimodal models rarely work out of the box. Companies that skimp here often regret it when performance disappoints.
Stay tuned to research. The field moves fast, with new approaches emerging constantly. What struggled last year might work today—if you know where to look.
Key Takeaways
- Multimodal AI model limitations stem from fundamental architectural challenges in fusing different information types
- Context understanding problems and cross-modal reasoning failures occur frequently in production environments
- Real-world deployments reveal gaps between laboratory performance and practical effectiveness
- Researchers are developing improved fusion mechanisms, contrastive learning, and uncertainty quantification
- Enterprise adoption requires realistic expectations, rigorous testing, and human oversight
Frequently Asked Questions
What exactly are multimodal AI models?
They’re AI systems that process multiple input types together—usually mixing text, images, audio, and video. The goal is richer understanding by combining data streams, much like humans use sight, sound, and context together.
Why do multimodal systems struggle with conflicting information?
Current models don’t actually reason through conflicts—they just favor whichever data type their training emphasized more. There’s no real “thinking” about which source makes more sense in context.
Are multimodal systems always better than single-modality approaches?
Not necessarily. While helpful when data types complement each other, they add complexity and cost. Often, simpler single-input systems work better—especially when you don’t need cross-modal understanding.
How long until multimodal AI limitations are solved?
Don’t hold your breath. While progress continues, fundamental breakthroughs in how AI represents knowledge are needed. Expect gradual improvements rather than sudden perfection.
Should my organization avoid multimodal AI?
Not if it fits your needs—just go in eyes open. Pilot carefully, test thoroughly, and focus on applications where different data types truly enhance each other. Sometimes less really is more.












No Comments