

Fine-Tuning Large Language Models: What Actually Works
Fine-tuning large language models has become a cornerstone strategy for organizations seeking to adapt foundation models to their specific needs. However, many teams invest heavily in fine-tuning without understanding what it truly accomplishes—or whether it’s the right solution for their problem.
This guide cuts through the noise. We’ll explain how fine-tuning works, when it delivers genuine value, and explore cost-effective alternatives that might serve you better.

What Fine-Tuning Actually Does to Your Model: fine-tuning large language models
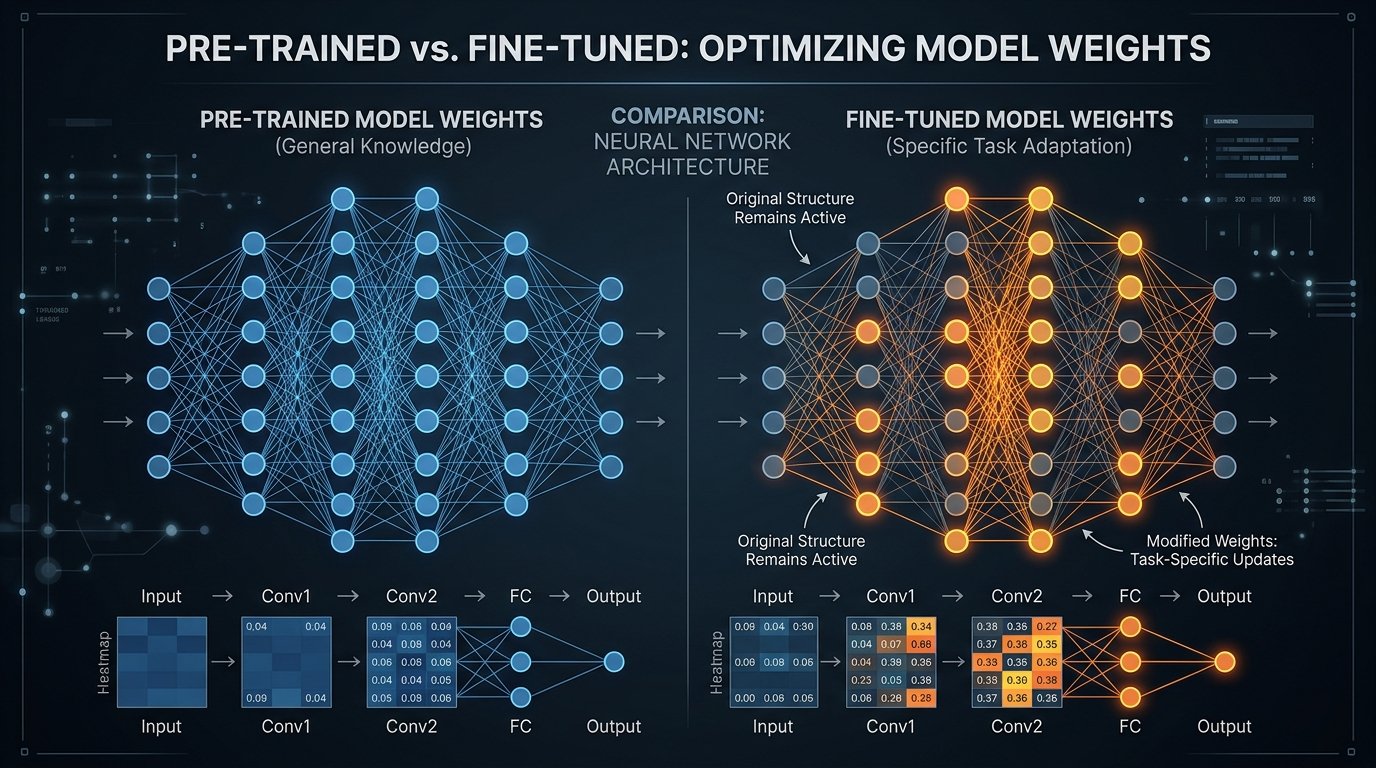
Fine-tuning large language models involves taking a pre-trained model and continuing its training on your specific dataset. Rather than training from scratch, you leverage the foundational knowledge already embedded in the model’s parameters.
Here’s what happens under the hood:
- The model’s existing weights get adjusted based on your new data
- Lower learning rates preserve general knowledge while adapting to your domain
- The process requires significantly fewer training examples than building from scratch
- Your model learns patterns specific to your use case or industry
Think of it like this: a foundation model is trained on billions of internet documents. Therefore, it understands general language patterns. When you fine-tune it on your medical records, legal documents, or customer support conversations, it learns to speak your specific language.
Fine-tuning adjusts the model’s behavior without retraining the entire architecture. This efficiency makes adaptation feasible for organizations without massive computing budgets.
Common Misconceptions About Fine-Tuning Benefits
Many teams approach fine-tuning with inflated expectations. Understanding what it cannot do prevents wasted resources and disappointment.
Misconception 1: Fine-Tuning Fixes Hallucinations
A widespread belief holds that fine-tuning eliminates hallucinations—when models generate plausible but false information. However, this isn’t accurate. Fine-tuning can reduce hallucinations in specific domains where your training data is accurate and abundant. It cannot eliminate the fundamental tendency.
Therefore, relying on fine-tuning alone to solve hallucination problems will disappoint you. Combine it with retrieval-augmented generation (RAG) or other grounding techniques.
Misconception 2: More Fine-Tuning Data Always Means Better Results
Quality matters far more than quantity. A dataset of 1,000 carefully curated, representative examples often outperforms 100,000 noisy or irrelevant samples.
Fine-tuning data requirements vary dramatically by task. Simple classification tasks need far fewer examples than complex reasoning or generation tasks.
Misconception 3: Fine-Tuning Is Cheaper Than Prompt Engineering
This assumption frequently leads organizations astray. While fine-tuning offers long-term benefits for repetitive tasks, the upfront costs are substantial. Conversely, prompt engineering—including few-shot examples and careful instruction design—costs almost nothing.
Prompt engineering improvements often appear faster. Therefore, always test prompt engineering thoroughly before committing to fine-tuning.
Misconception 4: Fine-Tuning Versus Prompt Engineering Is an Either-Or Choice
The best approach combines both. You might use prompt engineering to establish baseline performance, then fine-tune for production reliability and cost efficiency.
When Fine-Tuning Delivers Real ROI
Fine-tuning makes financial sense in specific scenarios. Identifying these situations prevents you from pursuing expensive solutions to problems that don’t require them.
High-Volume Production Tasks
If your application processes thousands of requests daily, fine-tuning becomes economical. A fine-tuned smaller model often costs less to run than repeatedly querying a larger model or paying per-token API fees.
For example, a customer service team handling 10,000 inquiries daily might fine-tune a model for ticket classification. The upfront investment pays back within weeks through reduced inference costs.
Domain-Specific LLM Adaptation
Highly specialized domains benefit tremendously from fine-tuning. Medical diagnosis, legal document analysis, or financial forecasting all involve specialized terminology and reasoning patterns that foundation models handle poorly.
Fine-tuning becomes essential when domain expertise cannot be easily captured through prompts alone. The model needs to internalize domain conventions.
Consistency and Reliability Requirements
Production systems often demand consistent output formats and reliable behavior. Fine-tuning provides this. A model trained on thousands of well-formatted examples will produce remarkably consistent results.
Fine-tuning reduces the variance in model outputs, making it suitable for regulated industries or critical applications.
Latency-Sensitive Applications
Smaller fine-tuned models respond faster than larger foundation models. Consequently, for real-time applications like chat systems or content moderation, fine-tuning a compact model can dramatically improve user experience.
Privacy and Data Security
Fine-tuning on private infrastructure means sensitive data never leaves your servers. Organizations handling confidential information—healthcare providers, law firms, financial institutions—often choose fine-tuning specifically for this reason.
You maintain complete control over model behavior and outputs.
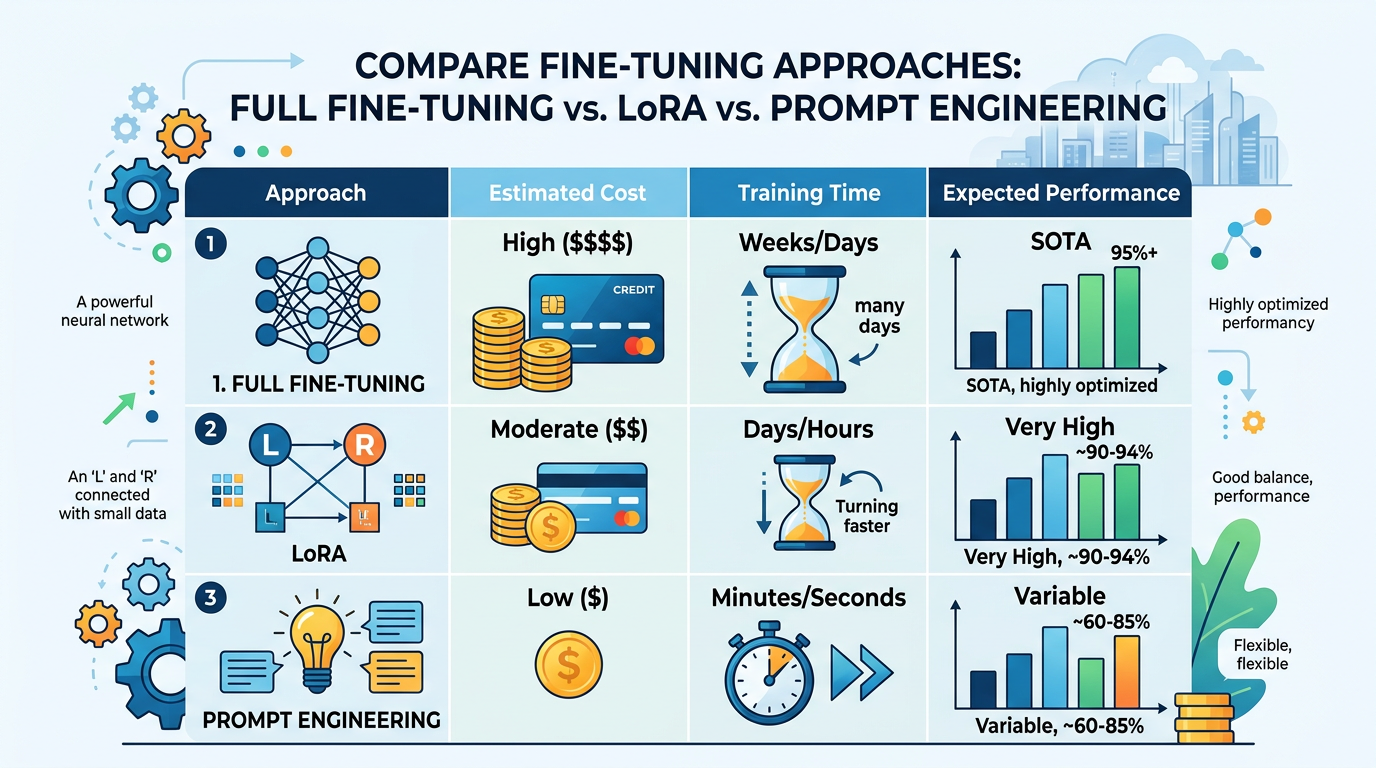
Cost-Effective Alternatives to Full Fine-Tuning
Full fine-tuning updates all model parameters, which is expensive and computationally intensive. Fortunately, several alternatives deliver similar results at a fraction of the cost.
Parameter-Efficient Fine-Tuning (PEFT)
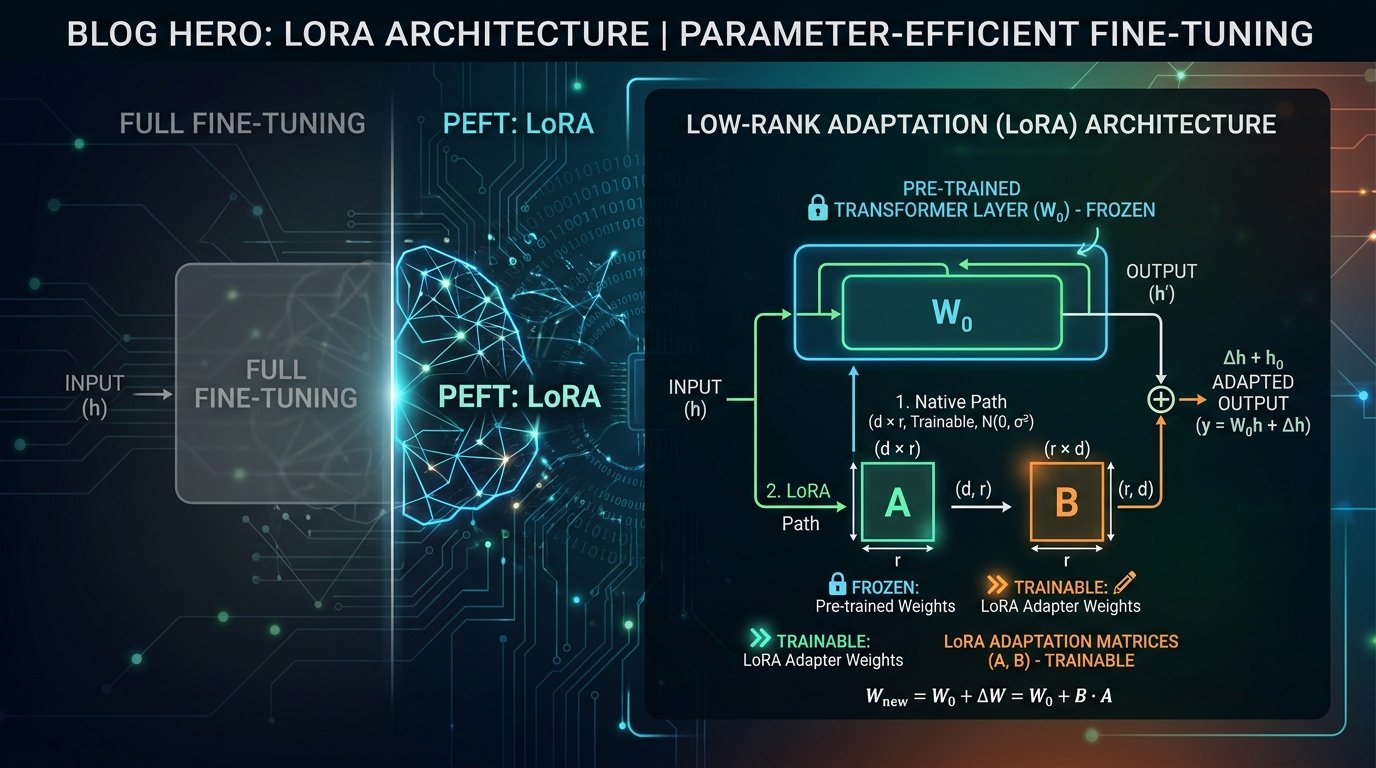
Parameter-efficient fine-tuning techniques update only a small subset of model parameters, dramatically reducing memory and computational requirements. The most popular approach is LoRA (Low-Rank Adaptation).
LoRA works by adding small, trainable matrices alongside the frozen pre-trained weights. This reduces trainable parameters by up to 99% while maintaining comparable performance.
LoRA versus full fine-tuning typically shows LoRA winning on cost and speed, with minimal performance trade-offs. For many organizations, LoRA is the obvious choice.
Prompt Engineering and In-Context Learning
Before investing in fine-tuning, exhaust prompt engineering possibilities. Modern LLMs excel at few-shot learning—learning from examples provided in the prompt itself.
A well-crafted prompt with 3-5 examples often achieves 80% of the performance that fine-tuning provides. Moreover, iterating on prompts takes hours, not weeks.
Prompt engineering works immediately without infrastructure investment.
Retrieval-Augmented Generation (RAG)
RAG combines language models with external knowledge bases. Rather than fine-tuning the model, you augment it with relevant documents or data at inference time.
This approach excels for knowledge-intensive tasks where your domain knowledge changes frequently. You update the knowledge base without retraining anything.
Fine-Tuning Data Requirements and Practical Considerations
If you do choose fine-tuning, understand your data requirements upfront. Most effective fine-tuning projects need 500-5,000 high-quality examples, depending on task complexity.
Before committing resources, assess whether you can realistically gather that volume of quality data. If not, alternative approaches may suit you better.
Measuring Success: Metrics That Matter
Fine-tuning success isn’t obvious. You need concrete metrics to determine whether the investment paid off.
Task-Specific Performance Metrics
The appropriate metrics depend entirely on your application. Classification tasks use accuracy, precision, recall, or F1-score. Generation tasks use BLEU, ROUGE, or human evaluation scores.
Define metrics before starting fine-tuning. This prevents post-hoc rationalization of mediocre results.
Inference Cost and Latency
Calculate the cost per inference before and after fine-tuning. If you fine-tune a smaller model, compare its total cost (fine-tuning overhead plus inference) against your baseline approach.
Measure latency improvements if that’s relevant to your use case.
Time to Production
How long did the entire fine-tuning pipeline take? This includes data collection, labeling, training, validation, and deployment. Compare this against alternative solutions.
Human Evaluation
Automated metrics tell only part of the story. Have domain experts evaluate a sample of model outputs. Do they match your quality standards? Are they better than the baseline?
Human evaluation catches failure modes that automated metrics miss.
Business Impact Metrics
Ultimately, fine-tuning must improve business outcomes. Track metrics like customer satisfaction, support ticket resolution time, or downstream task accuracy.
Connect technical improvements to business value. This justifies future investments and guides resource allocation.
Monitoring and Drift Detection
After deployment, monitor model performance continuously. Real-world data often differs from training data, causing performance degradation over time.
Establish alert thresholds. When metrics drop below acceptable levels, trigger retraining or investigation.
For more on managing LLM systems in production, see our guide to LLM deployment best practices.
Getting Started: A Practical Framework
Ready to evaluate fine-tuning for your use case? Follow this framework:
- Define your problem clearly: What specific task do you want to improve? What’s your baseline performance?
- Test prompt engineering first: Spend a few days optimizing prompts. This is your cheapest option.
- Assess data availability: Can you gather 500-5,000 quality examples? If not, reconsider.
- Calculate ROI: Estimate fine-tuning costs against expected benefits. Does the math work?
- Start small with LoRA: If proceeding, begin with parameter-efficient fine-tuning. Full fine-tuning is a later step if needed.
- Measure rigorously: Use both automated and human evaluation. Track business impact.
- Plan for maintenance: Fine-tuned models require monitoring and occasional retraining.
This systematic approach prevents expensive mistakes and ensures fine-tuning aligns with your actual needs.
Frequently Asked Questions
What’s the difference between fine-tuning and transfer learning?
Transfer learning is the broad concept of using knowledge from one task to improve another. Fine-tuning is a specific transfer learning technique where you retrain a pre-trained model on new data. All fine-tuning is transfer learning, but not all transfer learning is fine-tuning.
How long does fine-tuning typically take?
Timeline varies dramatically. Fine-tuning a small model on a GPU with 1,000 examples might take 1-2 hours. Fine-tuning a larger model on millions of examples could take days or weeks. Start with small experiments to gauge your infrastructure’s capabilities.
Can I fine-tune a model I don’t own?
Most commercial API providers (OpenAI, Anthropic, Google) offer fine-tuning services. You send your data to their infrastructure, they handle training, and you get a fine-tuned version. This is convenient but requires trusting the provider with your data.
What happens to my fine-tuned model when the base model updates?
Your fine-tuned model remains unchanged. However, you may eventually want to fine-tune the newer base model if it offers significant improvements. Plan for occasional re-tuning cycles.
Is fine-tuning worth it for small companies?
Not always. Small companies with limited data or budget should prioritize prompt engineering and RAG. Fine-tuning becomes worthwhile as volume and data availability grow. Start lean and scale fine-tuning investments as business needs justify them.
The Bottom Line: Fine-tuning large language models is powerful but not always necessary. Thoroughly evaluate your specific situation before committing resources. Often, simpler approaches like prompt engineering or parameter-efficient fine-tuning deliver better ROI. When you do fine-tune, measure results rigorously and maintain the system post-deployment. With this disciplined approach, fine-tuning becomes a strategic advantage rather than an expensive experiment.















No Comments