

multimodal AI models explained. Ever wondered how AI can understand both pictures and words at the same time? That’s multimodal AI for you. Unlike traditional systems that handle one type of data—like text or images—these advanced models juggle multiple inputs: text, images, audio, video, and more. By 2026, this technology has become more accessible and powerful, making it a game-changer for businesses and individuals alike.
In this guide, we’ll break down how multimodal AI works, explore its real-world uses, and give you tips to start using it effectively. Whether you’re running a business, coding apps, or just curious about AI, understanding these models is key to staying ahead in tech.

What Are Multimodal AI Models
Multimodal AI models are a big step forward in AI technology. Instead of focusing on one type of data, they process multiple inputs at once. Picture this: an AI that can analyze an image, read its caption, and listen to a related audio clip—all at the same time.
Traditional AI models stick to one lane. A vision model handles images, while a language model deals with text. Multimodal AI, though, bridges these gaps by combining different data types. This lets machines understand context better, much like how humans use sight, sound, and words together.
The real magic happens when these models make cross-modal connections. For example, when AI sees a photo and reads its description, it links visual elements to textual ideas. This dual understanding makes the AI smarter and more adaptable than single-mode systems.
Vision language models are a standout in this category. They’re great at tasks that require both visual and text understanding. Think generating image captions, answering questions about photos, or even creating images from text prompts. Their versatility makes them useful in countless ways.

How Multimodal AI Works in 2026
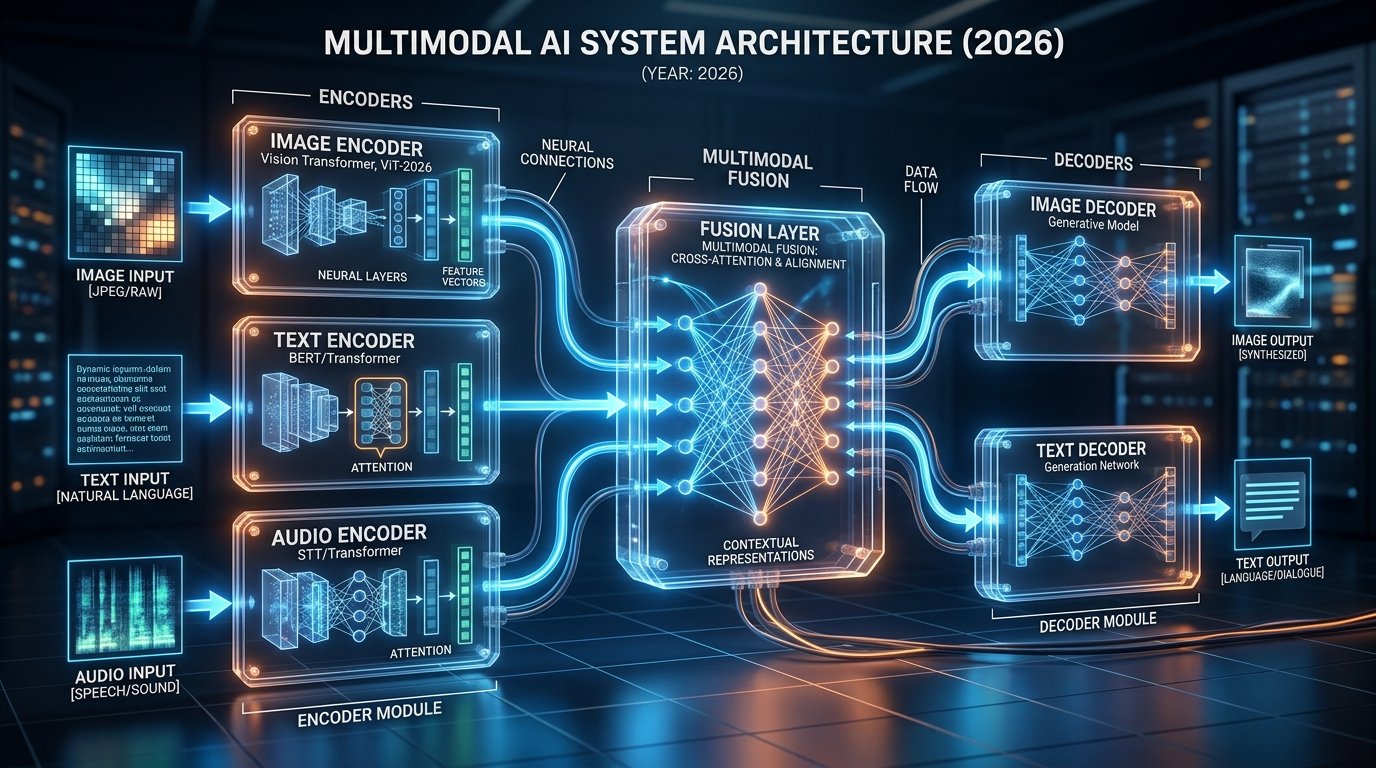
To understand multimodal AI, let’s peek under the hood. These systems use specialized encoders for each data type. An image encoder processes visuals, a text encoder handles words, and an audio encoder deals with sound. Each encoder converts its data into a common format.
The fusion layer is where the magic happens. It combines these representations into a unified understanding. In 2026, most systems use attention mechanisms to prioritize important information across inputs. This lets the AI focus on what matters most in a given context.
Cross-modal AI has come a long way. Modern systems rely on transformer-based models, which excel at spotting relationships between different data types. These transformers use self-attention to weigh the importance of inputs, making them great at handling complex scenarios.
Training these models requires massive datasets with aligned examples across modalities. Think images paired with captions or videos with transcripts. The AI learns by spotting patterns and correlations. Advances in self-supervised learning mean less need for labeled data, making the process smoother.
In 2026, most commercial systems use pre-trained foundation models. These large-scale models have already learned general patterns from huge datasets. Developers fine-tune them for specific tasks, cutting down on development time and resources. This approach has made powerful multimodal AI more accessible.
The process is straightforward: inputs come in, encoders process them, the fusion layer combines everything, and a decoder generates the output. This streamlined setup ensures efficient handling of complex inputs.
Real-World Applications and Use Cases
Multimodal AI is everywhere in 2026. Healthcare providers use it to analyze medical images alongside patient records and doctor’s notes, improving diagnostics. It spots patterns that single-mode systems might miss, leading to better patient care.
Content creation has gotten a boost too. Marketers use multimodal tools to create coordinated campaigns across text, images, and video. The best free AI video generators in 2026 let users craft polished content from simple text prompts. Similarly, free AI tools available today now include features once reserved for premium platforms.
E-commerce has embraced multimodal AI to enhance shopping. Customers can snap photos of items they like and get recommendations for similar products. The AI analyzes visuals, text descriptions, and user preferences, making shopping faster and more intuitive.
Accessibility is another big win. Multimodal AI helps visually impaired users by describing images in detail. It identifies objects, reads text, and provides context. For hearing-impaired users, it generates accurate captions and converts speech to text in real time.
Education has seen major benefits too. Interactive tutoring systems combine text, visuals, and audio to create personalized learning experiences. These systems adapt to different learning styles and provide feedback across multiple dimensions.
Autonomous vehicles rely on multimodal AI to navigate safely. They process camera feeds, radar data, GPS info, and maps simultaneously. This multi-sensor approach makes driving decisions smarter and safer.
Customer service has evolved with multimodal chatbots that understand images, documents, and spoken language. Customers can now include photos or screenshots when describing issues. The AI analyzes all inputs together, offering faster, more accurate solutions.

Popular Multimodal AI Platforms Today
Several platforms lead the multimodal AI scene in 2026. OpenAI’s GPT-5 Vision is a top pick, excelling at tasks like visual question answering and image captioning. Its API makes it easy for developers to build custom apps.
Google’s Gemini Ultra is another powerhouse, handling text, images, audio, and video with impressive accuracy. It shines in education and content analysis, especially for global businesses.
Anthropic’s Claude 3.5 focuses on safety and accuracy, making it popular in legal and finance sectors. It’s great at analyzing complex documents with both text and images.
Microsoft’s Copilot Vision integrates seamlessly with Office apps, letting users interact with documents using natural language and visuals. It’s a productivity booster for many.
Meta’s ImageBind connects six modalities—images, video, audio, text, depth, and thermal data. This broad integration opens doors for augmented reality and immersive experiences.
Runway ML caters to creative professionals with tools for video editing and content generation. Midjourney continues refining its image generation, letting users combine text prompts with reference images for precise results.
Open-source options like LLaVA and BLIP-2 are gaining traction. They offer powerful features without licensing costs, encouraging innovation and transparency.
Multimodal AI Models Explained: Getting Started
Starting with multimodal AI doesn’t require deep technical know-how. First, figure out your goals. Are you improving content creation, customer service, or data analysis? Knowing your objectives helps you pick the right tools.
Begin with user-friendly platforms offering free tiers. ChatGPT Plus, for instance, lets you upload images and ask questions about them. Hands-on experience helps you understand what’s possible.
Experiment with different inputs. Try pairing an image with a detailed text prompt and see how the AI responds. This helps you learn how modalities complement each other.
For developers, dive into API documentation. Start simple—build an image captioning tool or a document analyzer. Many platforms offer sandbox environments for testing.
Consider online courses focused on multimodal AI. Coursera, edX, and Udacity offer programs updated for 2026. These often include hands-on projects to build your skills.
Join communities for support and knowledge sharing. Forums, Discord servers, and Reddit groups are great places to connect with other practitioners and stay updated on trends.
Keep ethical considerations in mind. These systems can inherit biases from training data, so always verify outputs and implement safeguards.
Integrate AI gradually. Start with specific tasks where it adds value, like drafting content or analyzing feedback. This lets your team adapt while seeing tangible benefits.
Stay informed—multimodal AI evolves fast. Follow industry publications and blogs to keep up with new developments.
Think about how multimodal AI works with other tech you use. If you’re exploring AI agents for small business, multimodal features can boost their effectiveness. Understanding the differences between AI agents and chatbots helps you choose the right tools.

Frequently Asked Questions
What makes multimodal AI different from traditional AI?
Multimodal AI handles multiple data types at once—like text, images, and audio—while traditional AI sticks to one. This lets multimodal systems understand context better, much like how humans use multiple senses.
Can small businesses benefit from multimodal AI in 2026?
Absolutely. Affordable and free tools make it accessible. Small businesses use it for content creation, customer service, and more. The efficiency gains often justify the investment.
Do I need programming skills to use multimodal AI?
Not really. Many platforms have user-friendly interfaces. But coding skills help if you want to build custom solutions or integrate AI into existing systems.
How accurate are multimodal AI models in 2026?
Accuracy varies by task and platform. Leading models excel at common tasks like image captioning, but they can still make mistakes. Always verify critical outputs.
What are the main challenges with multimodal AI?
Key challenges include computational demands, data privacy, biases in training data, and aligning different modalities effectively. Despite these, the tech keeps advancing rapidly.
Multimodal AI is transforming industries and daily life. By understanding these models as explained here, you’re ready to harness their potential. As they evolve, they’ll create even more opportunities across fields. Start exploring now to stay ahead.















No Comments